-
 Thiết kế website chuyên nghiệp là mảng dịch vụ cốt lõi của chúng tôi với nhiều năm kinh nghiệm triển khai hàng nghìn dự án web lớn nhỏ cho các tập đoàn, doanh nghiệp trong và ngoài nước.
Thiết kế website chuyên nghiệp là mảng dịch vụ cốt lõi của chúng tôi với nhiều năm kinh nghiệm triển khai hàng nghìn dự án web lớn nhỏ cho các tập đoàn, doanh nghiệp trong và ngoài nước. -
 Smartphone App là mảng dịch vụ quan trọng phát triển cực nhanh và mạnh của chúng tôi đã và đang đáp ứng nhu cầu bùng nổ của thị trường App trên thiết bị di động trong nước và quốc tế.
Smartphone App là mảng dịch vụ quan trọng phát triển cực nhanh và mạnh của chúng tôi đã và đang đáp ứng nhu cầu bùng nổ của thị trường App trên thiết bị di động trong nước và quốc tế. -

Tích hợp AI
Kết nối, tích hợp AI là dịch vụ giúp doanh nghiệp nhanh chóng đưa trí tuệ nhân tạo vào hệ thống hiện có hoặc xây dựng nền tảng mới thông minh hơn. Giải pháp tối ưu, linh hoạt, giúp nâng cao hiệu quả bán hàng, chăm sóc khách hàng và quản trị, sẵn sàng cho kỷ nguyên số. -
 Drupal CMS là hệ quản trị nội dung mã nguồn mở mạnh hàng đầu thế giới hiện nay phù hợp làm nền tảng cho ứng dụng Web / App TMĐT lớn, cần tương tác, bảo mật và tùy biến backend cao.
Drupal CMS là hệ quản trị nội dung mã nguồn mở mạnh hàng đầu thế giới hiện nay phù hợp làm nền tảng cho ứng dụng Web / App TMĐT lớn, cần tương tác, bảo mật và tùy biến backend cao. -
 Drupal Hosting là dịch vụ lưu trữ và tối ưu hóa cho Web / App giúp ứng dụng luôn được kết nối tốc độ cao và online 24/7 để người dùng có thể truy cập từ bất kỳ địa điểm và thiết bị có kết nối Internet nào.
Drupal Hosting là dịch vụ lưu trữ và tối ưu hóa cho Web / App giúp ứng dụng luôn được kết nối tốc độ cao và online 24/7 để người dùng có thể truy cập từ bất kỳ địa điểm và thiết bị có kết nối Internet nào. -
 Tên miền, ứng dụng Web / App, e-mail, chứng thực số (SSL), và nhiều phần mềm khác sẽ đưa toàn bộ hoạt động một doanh nghiệp từ nền tảng truyền thống cũ sang nền tảng công nghệ mới hiện đại, năng động với chi phí cắt giảm tối ưu.
Tên miền, ứng dụng Web / App, e-mail, chứng thực số (SSL), và nhiều phần mềm khác sẽ đưa toàn bộ hoạt động một doanh nghiệp từ nền tảng truyền thống cũ sang nền tảng công nghệ mới hiện đại, năng động với chi phí cắt giảm tối ưu.
Big Data 2024: Top 6 công cụ phân tích dữ liệu vượt trội
Trên hành trình không ngừng phát triển Big Data, sự lựa chọn chính xác công cụ phân tích có thể là chìa khóa quyết định giữa việc khai thác mọi cơ hội hay lạc hậu trong cuộc đua công nghệ. Năm 2024 đánh dấu một bước tiến mới, khi các công cụ phân tích dữ liệu Big Data không chỉ tăng cường về hiệu suất mà còn đẩy mạnh về tính linh hoạt và sức mạnh tính toán. Trong bài viết này, Thiết kế web Giai Điệu sẽ cùng bạn khám phá "Top 6 công cụ phân tích dữ liệu Big Data mạnh mẽ nhất", giúp các doanh nghiệp và nhà nghiên cứu vượt qua những thách thức phức tạp của thời đại số.
1. Tìm hiểu về Big Data
1.1 Khái niệm Big Data
Big Data là thuật ngữ dùng để chỉ các tập dữ liệu lớn và phức tạp mà các phương tiện và công cụ truyền thống để lưu trữ, xử lý, và phân tích dữ liệu không thể xử lý một cách hiệu quả. Khái niệm này không chỉ tập trung vào kích thước của dữ liệu mà còn bao gồm các yếu tố khác như tốc độ tạo ra và lưu trữ dữ liệu, độ đa dạng của dữ liệu, và khả năng chính xác và tin cậy của dữ liệu.
1.2 Đặc điểm chính của Big Data
-
Volume (Lượng dữ liệu): Big Data thường đề cập đến lượng dữ liệu lớn, từ terabytes đến petabytes hoặc thậm chí exabytes và zettabytes. Dữ liệu này có thể bao gồm thông tin từ nhiều nguồn khác nhau như hệ thống máy chủ, thiết bị di động, cảm biến, mạng xã hội, và nhiều nguồn dữ liệu khác.
-
Velocity (Tốc độ): Dữ liệu trong Big Data thường được tạo ra, truyền tải và lưu trữ ở tốc độ nhanh chóng. Ví dụ, dữ liệu từ các thiết bị IoT (Internet of Things) có thể được tạo ra liên tục, và việc phân tích dữ liệu này yêu cầu sự xử lý thời gian thực.
-
Variety (Đa dạng): Dữ liệu trong Big Data không chỉ đến từ một nguồn duy nhất mà có thể là một hỗn hợp của dữ liệu cấu trúc, bất cấu trúc và bán cấu trúc. Các định dạng dữ liệu có thể bao gồm văn bản, hình ảnh, âm thanh, video, dữ liệu định lượng, và dữ liệu định tính.
-
Veracity (Chính xác): Một thách thức trong Big Data là đảm bảo tính chính xác và tin cậy của dữ liệu, đặc biệt khi dữ liệu này đến từ nhiều nguồn khác nhau với mức độ kiểm soát và chuẩn hóa khác nhau.
-
Value (Giá trị): Một trong những mục tiêu chính của việc phân tích Big Data là tìm ra thông tin hữu ích và giá trị từ dữ liệu này, giúp các tổ chức đưa ra quyết định thông minh và tối ưu hóa các quy trình kinh doanh.
2. Top 6 công cụ phân tích dữ liệu vượt trội
2.1 Apache Hadoop
Apache Hadoop là “ông trùm” trong danh sách nhờ khả năng xử lý dữ liệu lớn và phân tích dữ liệu phân tán. Hadoop cung cấp một hệ thống linh hoạt và có thể mở rộng để xử lý các công việc phức tạp và yêu cầu về dữ liệu.
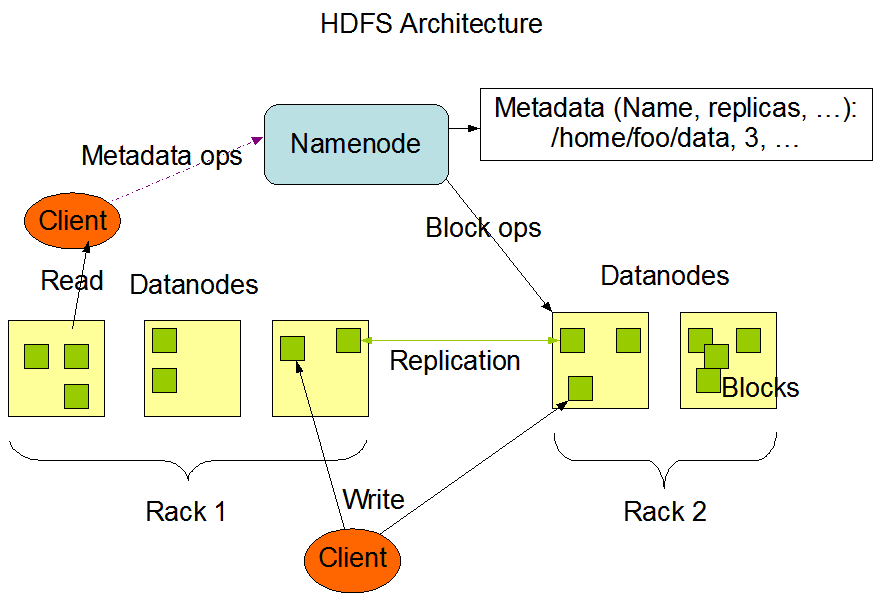
Các thành phần chính của Hadoop bao gồm:
-
Hadoop Distributed File System (HDFS): HDFS là hệ thống lưu trữ phân tán được thiết kế để lưu trữ dữ liệu lớn trên nhiều máy tính trong một cụm. Dữ liệu được chia nhỏ thành các block có kích thước cố định và lưu trữ trên các node khác nhau trong cụm.
-
MapReduce: MapReduce là một mô hình lập trình và một framework để xử lý và phân tích dữ liệu lớn trong Hadoop. Nó hoạt động bằng cách chia tác vụ xử lý thành hai phần: phần Map để xử lý và lọc dữ liệu, và phần Reduce để tổng hợp và phân tích kết quả.
-
YARN (Yet Another Resource Negotiator): YARN là một hệ thống quản lý tài nguyên trong Hadoop, cho phép nhiều ứng dụng chạy trên cùng một cụm Hadoop mà không xung đột về tài nguyên.
Hadoop được sử dụng rộng rãi trong nhiều ngành công nghiệp và lĩnh vực, bao gồm công nghệ thông tin, tài chính, y tế, và nghiên cứu khoa học. Nó cho phép các tổ chức lưu trữ, xử lý và phân tích dữ liệu lớn một cách linh hoạt và hiệu quả, đồng thời giúp giảm thiểu chi phí so với các giải pháp truyền thống.
2.2 Apache Spark
Apache Spark là một framework mã nguồn mở được thiết kế để xử lý và phân tích dữ liệu lớn một cách hiệu quả và linh hoạt. Được phát triển tại Đại học California, Berkeley, Spark cung cấp một cách tiếp cận mới cho việc xử lý dữ liệu lớn bằng cách tận dụng việc xử lý dữ liệu trong bộ nhớ (in-memory processing) và hoạt động song song (parallel processing).
Các đặc điểm chính của Apache Spark bao gồm:
Xử lý dữ liệu trong bộ nhớ: Spark có khả năng lưu trữ dữ liệu trung gian trong bộ nhớ thay vì chỉ lưu trữ trên đĩa như các hệ thống truyền thống. Điều này giúp tăng tốc độ xử lý dữ liệu lớn đáng kể.
-
Hỗ trợ nhiều loại công việc: Spark không chỉ hỗ trợ MapReduce như Hadoop mà còn hỗ trợ nhiều loại công việc xử lý dữ liệu khác như xử lý dữ liệu thời gian thực (stream processing), truy vấn dữ liệu tương tác (interactive querying) và xử lý đồ thị (graph processing).
-
API đa ngôn ngữ: Spark cung cấp API cho nhiều ngôn ngữ lập trình như Scala, Java, Python và R, giúp người dùng dễ dàng tích hợp với các ứng dụng và ngôn ngữ lập trình phổ biến.
-
Tích hợp với các công cụ và hệ thống khác: Spark có thể tích hợp với các hệ thống lưu trữ và xử lý dữ liệu khác như Hadoop, Cassandra, HBase, và Kafka, giúp tạo ra một hệ sinh thái phong phú cho việc xử lý dữ liệu lớn.
Apache Spark đang được sử dụng rộng rãi trong nhiều ngành công nghiệp và ứng dụng, từ phân tích dữ liệu, máy học đến xử lý dữ liệu thời gian thực. Sự kết hợp giữa hiệu suất cao, tính linh hoạt và tính năng đa năng của Spark đã làm cho nó trở thành một trong những công cụ phân tích dữ liệu hàng đầu hiện nay.
2.3 Datawrapper
Datawrapper là một công cụ trực quan hóa dữ liệu trực tuyến, cho phép người dùng tạo ra biểu đồ, bản đồ và các loại đồ họa khác từ dữ liệu của họ một cách dễ dàng và nhanh chóng. Được phát triển bởi Datawrapper GmbH, công cụ này nhấn mạnh vào việc tạo ra các biểu đồ đẹp mắt và dễ đọc, đồng thời tập trung vào trải nghiệm người dùng đơn giản và hiệu quả.
Một số đặc điểm của Datawrapper bao gồm:
-
Giao diện người dùng thân thiện: Datawrapper cung cấp một giao diện người dùng đơn giản và trực quan, giúp người dùng dễ dàng nhập dữ liệu và tạo biểu đồ mà không cần có kỹ năng lập trình hay thiết kế đồ họa.
-
Loạt biểu đồ đa dạng: Công cụ này hỗ trợ nhiều loại biểu đồ và đồ họa, bao gồm biểu đồ dạng cột, đường, tròn, bản đồ, và nhiều loại biểu đồ khác, cho phép người dùng tạo ra các biểu đồ phong phú và đa dạng.
-
Tùy chỉnh linh hoạt: Datawrapper cho phép người dùng tùy chỉnh các yếu tố của biểu đồ như màu sắc, font chữ, tiêu đề và chú thích, giúp tạo ra các biểu đồ có thẩm mỹ và phù hợp với nhu cầu cụ thể.
-
Tương thích đa nền tảng: Công cụ này có thể được tích hợp dễ dàng vào các trang web, blog hoặc báo cáo bằng cách nhúng mã nhúng được sinh ra tự động.
Bảo mật và quyền riêng tư: Datawrapper đảm bảo an toàn và bảo mật dữ liệu của người dùng, đồng thời cung cấp các tùy chọn quản lý quyền truy cập để kiểm soát việc chia sẻ dữ liệu và biểu đồ.
Datwrapper thích hợp cho mọi người từ các nhà báo, nhà nghiên cứu, đến những người làm việc trong lĩnh vực marketing và kinh doanh, giúp họ biểu diễn dữ liệu một cách trực quan và hiệu quả.
2.4 MongoDB
MongoDB là một hệ quản trị cơ sở dữ liệu phi quan hệ (NoSQL) mã nguồn mở, được thiết kế để xử lý và lưu trữ dữ liệu phi cấu trúc và có cấu trúc linh hoạt. Được phát triển bởi MongoDB Inc., nó cung cấp một cách tiếp cận hiệu quả và mạnh mẽ cho việc lưu trữ và truy vấn dữ liệu lớn và đa dạng.
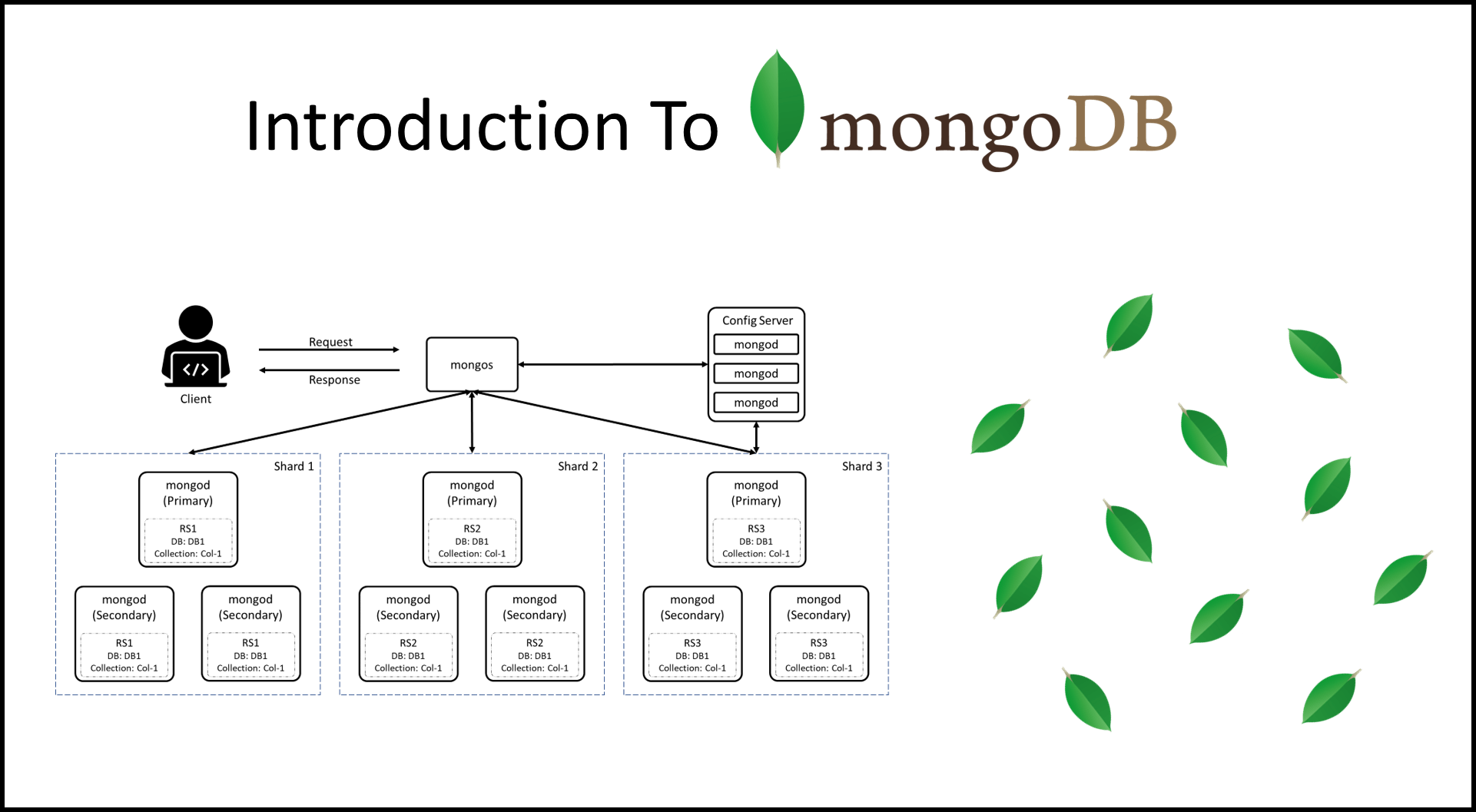 Một số đặc điểm và tính năng chính của MongoDB bao gồm:
Một số đặc điểm và tính năng chính của MongoDB bao gồm:
-
Tính linh hoạt: MongoDB cho phép lưu trữ dữ liệu theo một cấu trúc tài liệu linh hoạt, không cần phải tuân theo một schema cố định như trong cơ sở dữ liệu quan hệ. Điều này cho phép người dùng lưu trữ dữ liệu dưới dạng tài liệu JSON (BSON), giúp tạo ra một cấu trúc dữ liệu linh hoạt và dễ dàng thay đổi theo nhu cầu.
-
Tính mở rộng dễ dàng: MongoDB hỗ trợ mô hình dữ liệu phân tán và có thể mở rộng một cách dễ dàng bằng cách thêm vào các node mới vào cụm MongoDB, giúp nâng cao khả năng chịu tải của hệ thống mà không gặp phải sự gián đoạn.
-
Tính tương thích cao: MongoDB hỗ trợ các tập lệnh truy vấn phong phú và mạnh mẽ, giúp người dùng thực hiện các thao tác truy vấn phức tạp trên dữ liệu một cách dễ dàng và hiệu quả.
-
Khả năng xử lý dữ liệu lớn và thời gian thực: MongoDB được tối ưu hóa để xử lý dữ liệu lớn và thời gian thực, cho phép người dùng xử lý các ứng dụng yêu cầu cao về dữ liệu một cách hiệu quả và linh hoạt.
Cộng đồng mạnh mẽ và hỗ trợ đa nền tảng: MongoDB có một cộng đồng lớn và tích cực, cung cấp tài liệu phong phú, hướng dẫn và hỗ trợ từ cộng đồng, giúp người dùng dễ dàng tham gia và sử dụng MongoDB trên nhiều nền tảng khác nhau.
MongoDB thường được sử dụng trong các ứng dụng web, phân tích dữ liệu, Internet of Things (IoT), và các ứng dụng có yêu cầu cao về dữ liệu linh hoạt và mở rộng. Đặc biệt, nó phù hợp cho các dự án với yêu cầu thay đổi cấu trúc dữ liệu thường xuyên hoặc yêu cầu tính mở rộng cao.
2.5 RapidMiner
RapidMiner là một platform phân tích dữ liệu mã nguồn mở mạnh mẽ, cho phép các nhà phân tích dữ liệu và nhà nghiên cứu tạo ra các quy trình phân tích dữ liệu phức tạp một cách dễ dàng và linh hoạt. Được phát triển bởi RapidMiner Inc., công cụ này cung cấp một loạt các tính năng và công cụ giúp người dùng khai thác và hiểu sâu hơn về dữ liệu của họ.
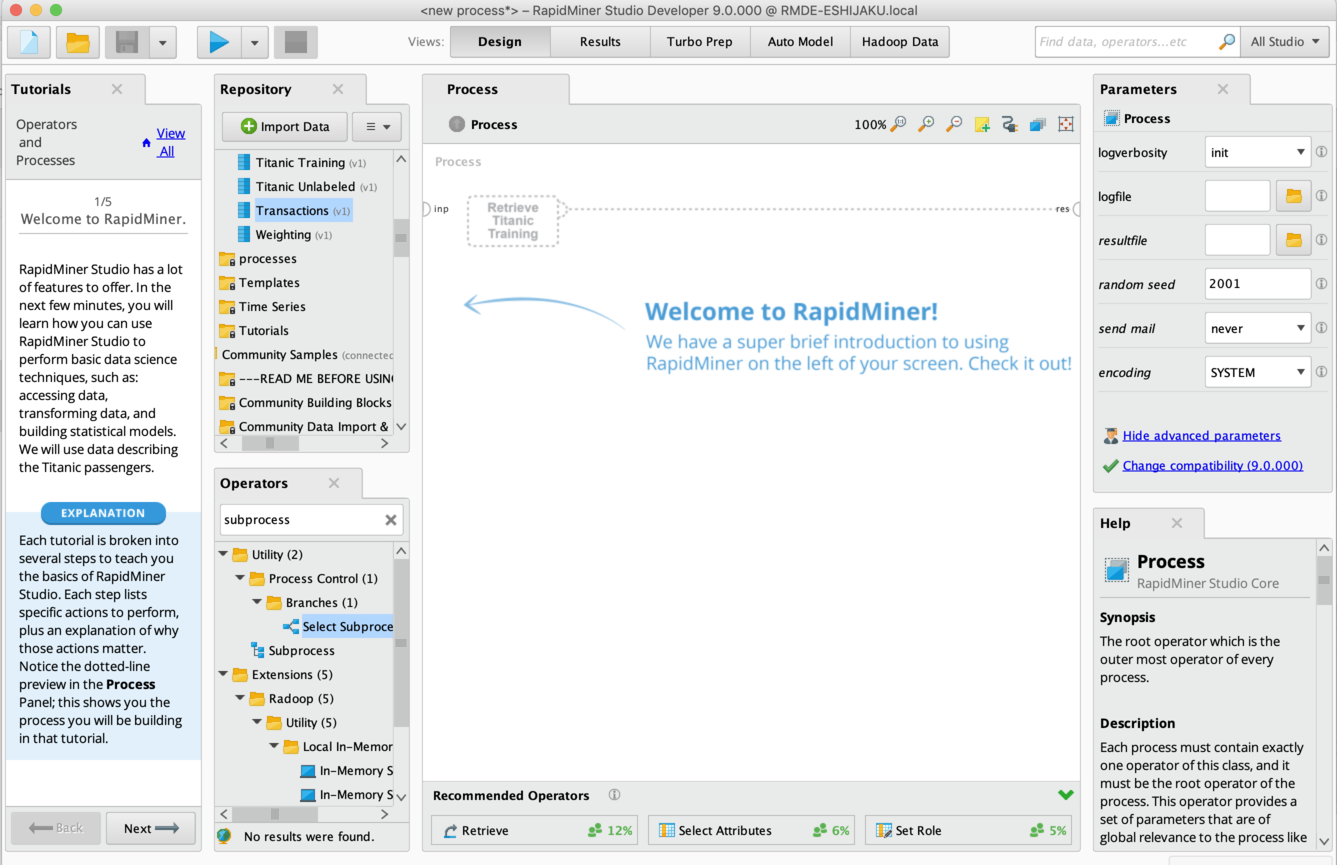
Một số đặc điểm và tính năng chính của RapidMiner bao gồm:
-
Giao diện người dùng đồ họa (GUI) trực quan: RapidMiner cung cấp một giao diện người dùng đồ họa trực quan và dễ sử dụng, cho phép người dùng kéo và thả các thành phần để tạo ra các quy trình phân tích dữ liệu một cách dễ dàng và nhanh chóng.
Thư viện công cụ đa dạng: RapidMiner cung cấp một loạt các công cụ và toán tử phân tích dữ liệu đa dạng, bao gồm tiền xử lý dữ liệu, phân tích thống kê, học máy, khai phá dữ liệu, và nhiều tính năng khác, giúp người dùng thực hiện các tác vụ phân tích dữ liệu từ đơn giản đến phức tạp. -
Tích hợp linh hoạt: RapidMiner có khả năng tích hợp với nhiều nguồn dữ liệu khác nhau như cơ sở dữ liệu, tệp tin, các dịch vụ web và nhiều nguồn dữ liệu khác, cho phép người dùng trích xuất dữ liệu từ các nguồn khác nhau để phân tích.
-
Hỗ trợ học máy và AI: RapidMiner cung cấp các công cụ và thuật toán học máy tiên tiến, giúp người dùng xây dựng và đào tạo các mô hình học máy để dự đoán và phân loại dữ liệu.
-
Tính mở rộng và tuỳ chỉnh: RapidMiner cho phép người dùng mở rộng và tùy chỉnh các tính năng và chức năng thông qua các plugin và API, giúp phù hợp với nhu cầu cụ thể của từng dự án phân tích dữ liệu.
RapidMiner thường được sử dụng trong các ngành công nghiệp như tài chính, bán lẻ, y tế, và marketing để thực hiện các tác vụ như dự đoán, phân loại, phân tích đám đông, và tối ưu hóa quy trình kinh doanh. Đặc biệt, RapidMiner phù hợp cho cả người mới bắt đầu và những chuyên gia phân tích dữ liệu với các yêu cầu phức tạp.
2.6 Tableau
Tableau là một platform phân tích và trực quan hóa dữ liệu hàng đầu, cho phép người dùng tạo ra các biểu đồ, bảng điều khiển và báo cáo trực quan từ dữ liệu của họ một cách dễ dàng và linh hoạt. Được phát triển bởi Tableau Software, công cụ này được ưa chuộng trong cả doanh nghiệp và cộng đồng phân tích dữ liệu vì khả năng mạnh mẽ và giao diện người dùng thân thiện.
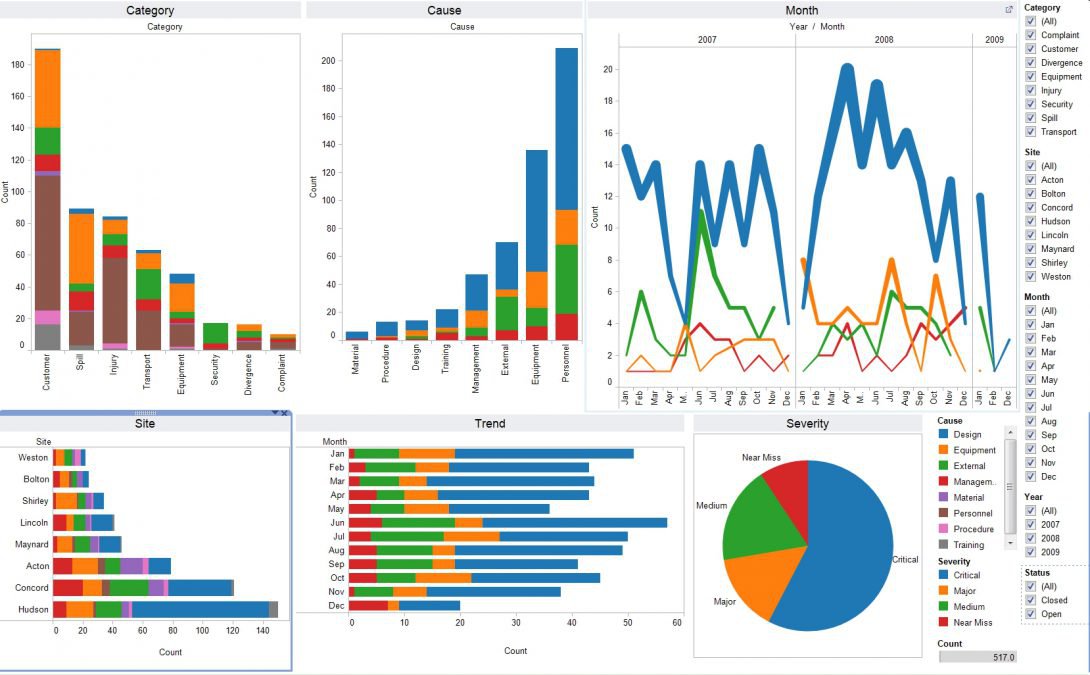 Một số đặc điểm và tính năng chính của Tableau bao gồm:
Một số đặc điểm và tính năng chính của Tableau bao gồm:
-
Giao diện người dùng trực quan và dễ sử dụng: Tableau cung cấp một giao diện người dùng đồ họa trực quan và dễ sử dụng, cho phép người dùng kéo và thả các trường dữ liệu để tạo ra các biểu đồ và bảng điều khiển một cách nhanh chóng và linh hoạt.
-
Đa dạng các loại biểu đồ và đồ họa: Tableau hỗ trợ nhiều loại biểu đồ và đồ họa khác nhau như biểu đồ cột, đường, tròn, scatter plot, bản đồ, histogram và nhiều loại biểu đồ khác, giúp người dùng hiểu rõ hơn về dữ liệu của họ.
-
Kết nối đa nguồn dữ liệu: Tableau cho phép người dùng kết nối và tổ chức dữ liệu từ nhiều nguồn khác nhau như cơ sở dữ liệu, bảng tính Excel, tệp văn bản, dịch vụ đám mây và nhiều nguồn dữ liệu khác.
-
Tích hợp với công nghệ thông tin hiện có: Tableau có khả năng tích hợp với các hệ thống và công nghệ thông tin hiện có trong tổ chức như SQL Server, Amazon Redshift, Google BigQuery, Salesforce và nhiều hệ thống khác.
-
Tính năng tương tác và chia sẻ: Tableau cho phép người dùng tương tác với dữ liệu thông qua các bộ lọc, tham số và tiêu đề tùy chỉnh, cũng như chia sẻ bảng điều khiển và báo cáo với người khác thông qua các tệp workbook hoặc bản xuất.
Tableau thường được sử dụng trong nhiều ngành công nghiệp và lĩnh vực như tài chính, bán lẻ, y tế, sản xuất và tiếp thị để phân tích dữ liệu, tạo ra báo cáo và đưa ra quyết định chiến lược dựa trên dữ liệu. Đặc biệt, Tableau được đánh giá cao về khả năng tạo ra các trực quan hóa dữ liệu đẹp mắt và dễ hiểu.
Tổng kết
Trong bối cảnh dữ liệu lớn ngày càng trở nên quan trọng và phổ biến, việc lựa chọn các công cụ phân tích dữ liệu phù hợp là một yếu tố quyết định cho sự thành công của các tổ chức và doanh nghiệp. "Top 6 công cụ phân tích dữ liệu Big Data vượt trội" đã được liệt kê ở trên không chỉ cung cấp các tính năng mạnh mẽ mà còn đáp ứng được các yêu cầu ngày càng phức tạp của thị trường và công nghệ. Với sự kết hợp thông minh của các công cụ này, các tổ chức và nhà nghiên cứu có thể khai thác toàn bộ tiềm năng của dữ liệu lớn, tạo ra giá trị và đạt được sự cạnh tranh ưu việt trong thế giới kinh doanh ngày nay.